partitioning
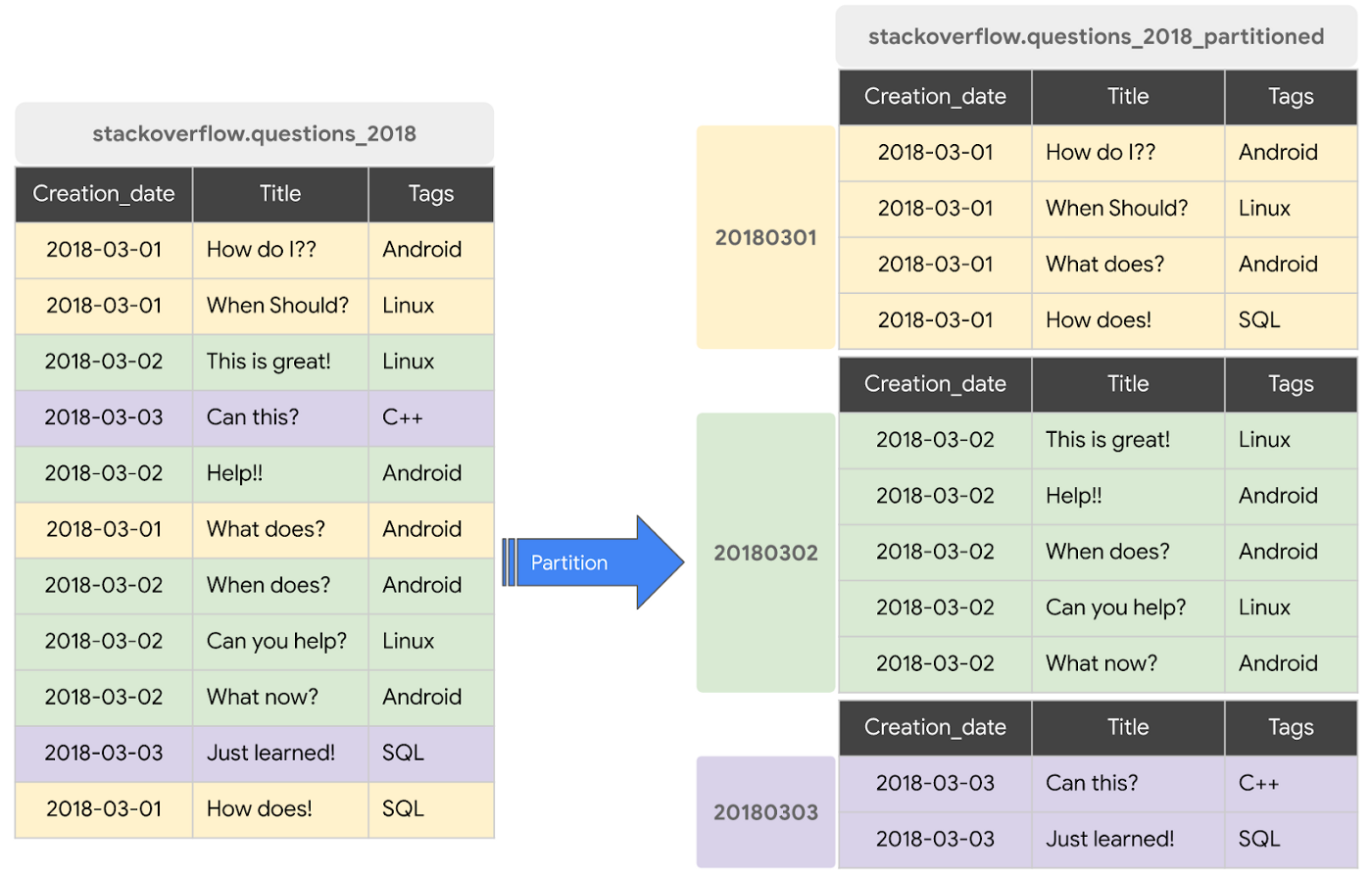
- 테이블에 저장된 데이를 논리적으로 구성하고 제어하는 방법이다.
- 파티션을 사용하면 테이블을 파티션이는 더 작고 관리하기 쉬운 조각으로 나눌 수 있다.
- 서로 다른 파티션은 물리적으로 다른 위치에 저장한다.
- 대용량 논리테이블을 파티션으로 분할하여 필요 부분만 조회할 수 있다.
- 낮은 카디널리티 필드에 적합하다.
- 일반적으로 유일한 값의 수가 수천 개 이하면 낮다고 보면 좋다.
- 테이블을 너무 잘게 파티셔닝한다면 그만큼 메타데이터가 증가하고 이는 효율성이 떨어진다.
- 대표적인 파티셔닝 종류는 Time-based partitioning & Range-based partitioning 이 존재한다.
- Time-based partitioning 은 날짜 또는 타임스탬프와 같은 특정 시간 열 기반으로 데이터를 구성한다. 시간이 지남에 따라 변경되는 데이터로 작업하고 자주 쿼리할 필요가 없는 많은 양의 데이터를 처리하는 데 유용하다.
- Range-based partitioning 은 ID 또는 상태와 같은 특정 숫자 또는 문자열 기반으로 데이터를 구성한다. 특정 기준에 따라 많은 양의 데이터를 더 작고 관리하기 쉬운 조각으로 나누는 데 유용하다
clustering
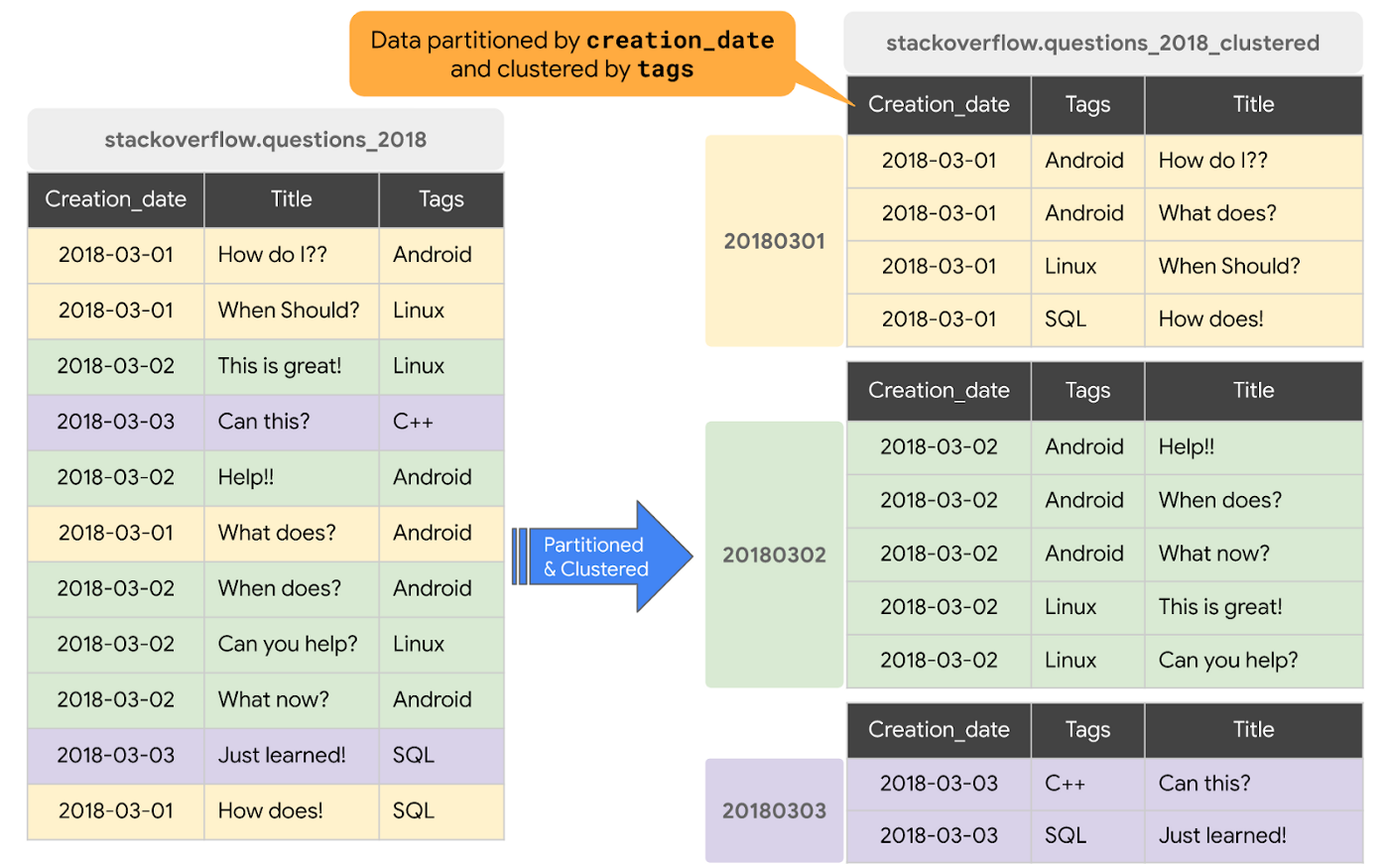
- 클러스터링은 테이블에 저장된 데이터를 물리적으로 구성하고 정렬하는 방법이다.
- 클러스터링을 사용하면 테이블에서 데이터의 물리적 순서를 결정하는 클러스터링 키로 하나 이상의 열을 설정할 수 있다.
- 특정 열 기반으로 클러스터링함으로써 보다 효율적이고 빠른 쿼리 처리가 가능하게 데이터를 물리적으로 배열한다.
- 특정 유형의 쿼리(특히 클러스터링 키 값을 기반으로 데이터를 필터링하는 쿼리)의 성능을 높일 수 있다. 클러스터링 키 값을 기준으로 데이터를 필터링하면, 데이터가 테이블의 연속 블록에 저장되므로 더 빠르게 스캔하고 검색할 수 있다.
- 단, 클러스터링에는 추가 스토리지 및 처리 리소스가 필요하므로 구현하기 전 비용을 고려해야 한다. 또한 클러스터링은 테이블에 있는 데이터의 물리적 배열을 변경하기 때문에 모든 사용 사례에 최선의 선택이 아닐 수 있다. 클러스터링이 데이터 및 쿼리에 적합한지 확인하려면 데이터 크기, 쿼리 빈도 및 실행하는 쿼리 유형등을 고려해야 한다.
comparison
| partitioning | clustering | |
|---|---|---|
| 쿼리목적 | 테이블 일부만 스캔하여 쿼리 성능을 향상시키고 싶을 때 | 특정 열을 필터링하여 일부 블록만 스캔하여 쿼리 속도를 향상시키고 싶을때 |
| 키 | 파티션에는 단 하나의 칼럼만을 사용할 수 있다. | 클러스터링 키는 여러개를 사용할 수 있다. |
| 테이블 크기 | 작은 테이블에서도 사용가능하다. | 쿼리 대상 테이블의 크기가 1GB 이하인 경우 성능 이점을 제공하지 않는다. |
| 비용 | 쿼리비용 추정이 용이하다. | 엄격한 쿼리비용 추적이 어렵다. |